
Abstract
This study introduces a low-power analog integrated Euclidean distance radial basis function classifier. The high-level architecture is composed of several Manhattan distance circuits in connection with a current comparator circuit. Notably, each implementation was designed with modularity and scalability in mind, effectively accommodating variations in the classification parameters. The proposed classifier’s operational principles are meticulously detailed, tailored for low-power, low-voltage, and fully tunable implementations, specifically targeting biomedical applications. This design methodology materialized within a 90 nm CMOS process, utilizing the Cadence IC Suite for the comprehensive management of both the schematic and layout design aspects. During the verification phase, post-layout simulation results were meticulously cross-referenced with software-based classifier implementations. Also, a comparison study with related analog classifiers is provided. Through the simulation results and comparative study, the design architecture’s accuracy and sensitivity were effectively validated and confirmed.
Keywords: analog VLSI; low-power design; cardiovascular disease; machine learning; analog classifiers
1. Introduction
In the realm of biomedical engineering, the integration of machine learning (ML) stands as a pioneering force reshaping the landscape of healthcare and technological advancements [1]. ML algorithms have emerged as invaluable tools, revolutionizing the analysis of complex biological data, such as genomic sequences, medical images, and physiological signals [2]. Through sophisticated pattern recognition and predictive modeling, these algorithms unveil intricate relationships within biomedical datasets, offering insights that were once elusive [3]. This synergy between machine learning and biomedical engineering not only expedites the discovery of novel treatments and diagnostic tools, but also fosters personalized healthcare approaches, tailoring interventions to individual genetic profiles and disease susceptibilities [4].
The convergence of ML and biomedical engineering creates a new era of precision medicine, transcending traditional medical paradigms [5]. By harnessing vast datasets and employing intricate algorithms, researchers can decipher the underlying mechanisms of diseases, unlocking unprecedented avenues for early detection and intervention [6]. Moreover, these innovations catalyze the development of smart medical devices and systems, facilitating real-time patient monitoring, diagnostics, and therapy optimization [7]. As ML algorithms continue to evolve and adapt, the synergy with biomedical engineering not only augments our understanding of intricate biological systems, but also propels the translation of research findings into tangible solutions that enhance patient care and outcomes [8].
The fusion of wearable devices with ML in biomedical engineering represents a transformative synergy that redefines the landscape of personalized healthcare [9]. These wearable sensors, ranging from smartwatches to biosensing patches, generate a torrent of real-time physiological data, capturing intricate details of an individual’s health status [10]. ML algorithms, adept at deciphering patterns within these vast datasets, enable the extraction of meaningful insights, facilitating early disease detection, continuous monitoring, and personalized interventions [11]. This amalgamation not only empowers individuals to actively engage in their well-being, but also fosters a proactive healthcare approach, where predictive analytics and adaptive algorithms guide tailored interventions, optimizing health outcomes and revolutionizing the paradigm of preventive medicine [12].
Regarding biomedical engineering, the necessity of low-power solutions stands as a pivotal imperative, driving innovation towards more-efficient and -sustainable healthcare technologies [13]. The quest for low-power consumption in biomedical devices is paramount, particularly in wearable sensors, implantable devices, and point-of-care diagnostics [14]. These solutions not only enhance patient comfort and compliance, but also extend device lifespans while minimizing the need for frequent interventions or replacements [15]. Moreover, low-power technologies play a critical role in enabling continuous monitoring, facilitating real-time data acquisition and transmission without imposing excessive energy demands [16]. As the demand for portable, remote monitoring devices surges, low-power solutions not only optimize battery life, but also pave the way for the seamless integration of technology into everyday life, ensuring prolonged and unobtrusive monitoring for improved patient outcomes [17]. The development of such energy-efficient solutions represents a fundamental pillar in advancing biomedical engineering, fostering the creation of scalable, sustainable, and patient-centric healthcare innovations [18].
Emerging computing paradigms, like analog computing, are poised to revolutionize biomedical engineering by offering novel approaches to process and analyze complex biological data, with low power consumption [19,20,21]. Analog computing, with its ability to handle continuous signals and perform computations closer to the natural world’s analog nature, presents a promising frontier in modeling biological systems [19,20]. This paradigm’s unique capacity to mimic biological processes, such as neural networks or physiological responses, holds tremendous potential in decoding intricate biological mechanisms and optimizing healthcare solutions [19,20]. By leveraging the inherent parallelism and efficiency of analog computations, biomedical engineers can create innovative platforms capable of rapid and nuanced analysis of biological signals, leading to breakthroughs in diagnostics, personalized treatments, and the development of biologically inspired computing systems tailored to address healthcare challenges with unparalleled precision and efficiency [22].
Motivated by the necessity for low-power smart biosensors [23,24], this study combines sub-threshold analog computing techniques with ML methodologies [25]. The present work introduces a low-power (less than 430 nW), low-voltage (0.6
V), analog integrated Euclidean distance radial basis function (RBF) classifier, tailored for real-world biomedical classification problems [26]. This methodology is grounded upon an RBF mathematical model [27], employing two primary sub-circuits. Core components include an ultra-low-power Manhattan (approximating Euclidean) distance function circuit [28] and current comparator circuit [29]. Experiments were carried out using a TSMC 90nm CMOS technique, employing the Cadence IC design Suite, and contrasted with a software-oriented execution. Moreover, the efficiency of this design was validated via Monte Carlo assessment, affirming its responsiveness and operational effectiveness.
The remainder of this document is structured as outlined below. Section 2 covers the contextual framework of this research. This encompasses an examination of existing literature and the mathematical model employed. In Section 3, we introduce the outlined high-level configuration of the analog classifier. Moreover, a detailed analysis of the primary components constituting the analog classifier is presented. Section 4 delves into the validation of the proposed architecture using a real-world cardiovascular dataset. Included within this section are comparative evaluations between hardware and software implementations, along with sensitivity assessments. Section 5 comprises a comparative study and discussion of the findings. Lastly, in Section 6, conclusive remarks summarizing the discoveries and implications of this investigation are provided.
2. Background
2.1. Related Literature
The current global landscape is inundated with a diverse range of data formats—text, images, videos, and more—which are projected to continue growing significantly in the future [30,31]. Machine learning (ML) stands as a promising avenue for distilling meaning from this vast pool of data. Being interdisciplinary in nature, ML merges with mathematical domains like statistics, information theory, game theory, and optimization [27,32]. This fusion of methodologies and technologies acts as a conduit for effectively managing this deluge of data. Moreover, automated algorithms possess the capability to uncover meaningful patterns or hypotheses that might evade human perception. While traditionally confined to software execution, there is a rising trend towards adapting these algorithms and models for hardware-friendly implementations [33,34].
Three distinct hardware design methodologies emerge, each with its own merits and limitations. These approaches encompass analog, digital, and mixed-mode implementations. Digital circuits, commonly employed in ML applications, offer advantages in achieving heightened classification accuracy, adaptability, and programmability [35]. However, they pose significant challenges in terms of high power consumption and spatial requirements due to their intensive data transactions and rapid operations. In contrast, specialized analog hardware ML architectures offer cost-effective parallelism through low-power computation [36]. Yet, accuracy faces challenges due to imprecise circuit parameters caused by noise and limited precision. Furthermore, certain mixed-mode architectures leverage both analog and digital techniques to achieve reduced power consumption and compact footprints [37]. However, these solutions contend with additional costs associated with domain conversion.
Architectures tailored specifically to ML algorithms and models in an analog hardware implementation leverage circuits grounded in Gaussian functions [38]. A subsection consolidates the distinctive features of system-level implementations integrated with Gaussian function circuitry. The proposed ML systems encompass various neural networks such as radial basis function neural networks (RBF NNs) [39,40,41,42,43,44,45,46,47,48,49], offering a comprehensive design framework. The related works [41,44,45,48,50] have fabricated and tested the classifier. Either toy datasets or application-specific implementations have been analyzed. Additionally, these systems include other neural networks like multi-layer perceptron (MLP), the radial basis function network (RBFN) [44,50], the Gaussian RBF NN (GRBF NN) [51,52], the Gaussian mixture model (GMM) [53], Bayes classifiers [54], K-means-based classifiers [55], voting classifiers [56], fuzzy classifiers [57], threshold classifiers [58], and centroid classifiers [59]. Moreover, other algorithms and classifiers like support vector machine (SVM) [60,61,62], support vector regression (SVR) [63], single-class support vector domain description (SVDD) [64], pattern-matching classifiers [65,66], vector quantizers [67,68], a deep ML (DML) engine [69], a similarity evaluation circuit [70], a long short-term memory (LSTM) [71,72,73,74], and a self-organizing map (SOM) [75] are encompassed within this spectrum. Gaussian function circuits form the fundamental basis for executing two crucial functions essential to various ML algorithms: (a) kernel density and (b) distance computation. Most of these applications cater to input dimensions below 65 dimensions, with some instances not specifying an upper limit [40,50,51,67], thus accommodating high-definition image classification.
Based on the above analysis and bibliography, most classifiers presented have been general-purpose. More specifically, they presented a generalized topology and tested it on toy datasets [39,40,41,42,43,44,45,46,47,48,49]. On the other hand, there are application-specific implementations that combine data from real-world datasets related to biomedical engineering, computer vision, image classification, navigation, fuzzy control, sensor fusion, etc. [39,40,41,42,43,44,45,46,47,48,49]. To carry out an on-chip classification process, fundamental key issues such as implementing more complex features in the analog domain (feature extraction) need to be addressed [76,77]. Other solutions to this include a digital implementation and achieving conversion through low-power current-mode digital-to-analog converters (DACs) [78]. Additionally, reducing power consumption in the analog front-end, which performs the appropriate signal processing, is necessary [79]. Furthermore, the need for low-power non-volatile memories is evident, which will solve the issue of storing data extracted from training [80]. Obviously, the combination of pure analog with memristors or neuromorphic or mixed-signal implementations would be some of the solutions to the existing problems [81]. However, since the ultimate goal is low power consumption, a more-analog IC approach is desirable. Finally, choosing the appropriate algorithm for each dataset is crucial and should have its own weight in the study.
2.2. Mathematical Model
RBFs represent real, positive-valued functions reliant on the distance between an input vector and a fixed point [27,82]. The proximity of the input to the fixed point inversely correlates with the RBF’s value. These functions include the Euclidean, Manhattan, and polyharmonic spline, among others. Commonly employed for mathematical approximations, interpolations, serving as activation functions in neural networks (NN), or functioning as kernels in ML algorithms, RBFs hold versatile applications. A multivariate Euclidean RBF is formulated based on the Euclidean norm. The Euclidean distance, also known as the two-norm distance or Euclidean norm, quantifies the direct distance between two points in a Euclidean space. In ????????
, the Euclidean distance between two points, p and q, is computed using the Euclidean norm as follows:
The classifier’s output corresponds to the class having the shortest distance from the input vector:
Based on this distance metric, the overall classifier determines the winning class by applying the argmin operator in this metric.
The implementation presented in the next section is based on an approximation of the aforementioned mathematical model. This specific mathematical model describes the operation of the software-based classifier, which is approached with the proposed architecture. Additionally, the circuit used for distance calculation is also an approximation of the Euclidean norm of the software. The above approaches were made with the aim of low-power operation, that is to have an implementation with the minimum possible power supply and the operation of all transistors in the sub-threshold region (low-voltage and low-current). Furthermore, low power consumption is based on the behavior of the structural element itself (activation circuit), which does not lose its behavior even with small currents. Also, the same implementation could be achieved both using transistors operating in saturation (non power-efficient) and with a structural element that would approximate the Euclidean distance with greater accuracy (more-complex implementation). Finally, the high-level architecture itself could be different using more structural blocks, but it is not certain whether it would increase the accuracy.
3. Proposed Architecture and Main Circuits
Exploring the fundamental concept of the RBF-based classifier takes precedence in this segment. To illuminate the reasoning behind this particular design, envision a scenario: the classification of
separate classes (referred to as class), each with
inputs (features). This adaptability expands to include the accommodation of diverse input dimensions and classes.
The diagram illustrating the proposed structure for the analog integrated RBF classifier is illustrated in Figure 1. Following the formulation of the classification problem outlined previously, the classifier is composed of a singular current comparator (CC) block encompassing
inputs and an equivalent number of classes. Each of these classes comprises
sub-cells, delineating
features. These sub-cells operate as circuits embodying the Manhattan distance (as the approximation of the Euclidean one), receiving inputs. Their function involves computing the distance of an input vector
associated with a particular class by utilizing the Manhattan distance for each feature, as described in the mathematical model.
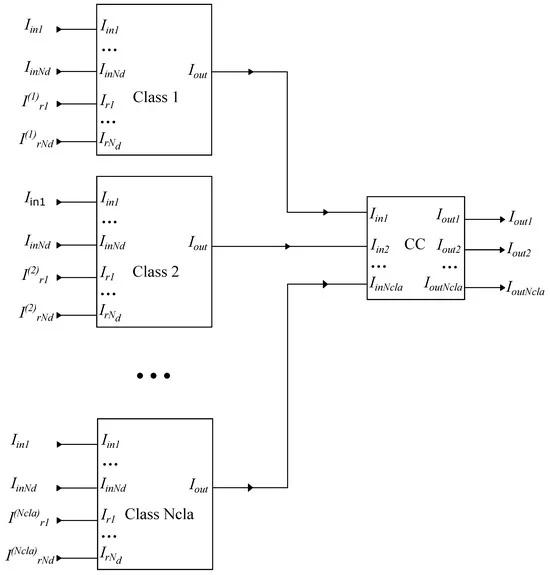
Figure 1. Analog integrated RBF-based classifier with classes and features. This is a conceptual design describing the proposed architecture.
Also, section analysis thoroughly examines the primary building circuits crucial for implementing the RBF-based classifier. Each classifier necessitates two key blocks: the class and a CC. Additionally, every cell demands two primary components: the Manhattan distance circuit (MDC) and cascode current mirrors (CMs). To uphold precision and reduce potential distortions, this summation process within a class is achieved by employing CMs, as shown in Figure 2. The dimensions of the transistors within each cascode current mirro.
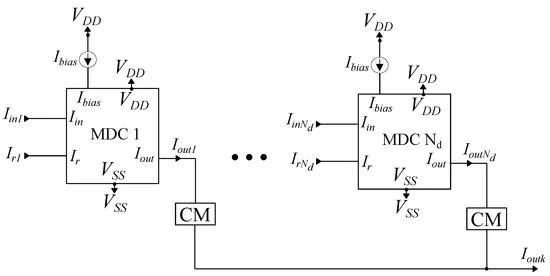
Figure 2. Analog integrated implementation of a class with features. Extra CMs are employed in order to deal with potential distortions.
To implement the Manhattan distance function as defined in the mathematical model, we utilized a current-mode MDC [28], illustrated in Figure 3. Operating in a translinear manner, this circuit approximates the mathematical expression:. The summation process within the current domain is straightforward, accomplished by connecting wires containing the currents. Moreover, to optimize the mirroring performance, even with low bias currents, cascode CMs have been integrated. The behavior of the circuit was verified through the simulation results in Figure 4. Information regarding the dimensions of the transistors can be found in Table 1.
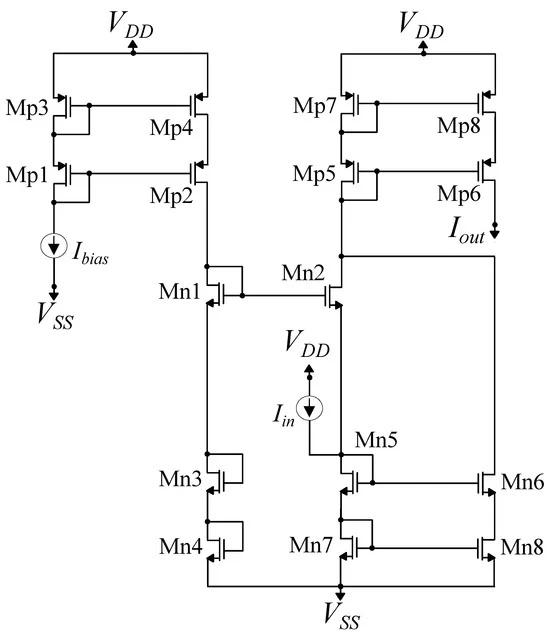
Figure 3. MDC for the realization of the Manhattan distance. is the output of the circuit, which has the lowest value for

Figure 4. Parametric analysis of the implemented MDC over the circuit’s parameters.
Table 1. MDC transistors’ dimensions.

The next circuit under consideration is the CC. Since, in this work, a 2-class classification problem is analyzed, a cascaded winner-takes-all (WTA) circuit was employed. This circuit is used as an argmax operator. In this work, since we need the smallest distance, the winner is described by the minimum output current (for a two-class problem). For a generic illustration, an argmin operator is necessary.
The analysis focuses on the behavior of a cascaded winner-takes-all (WTA) mechanism. To understand the modified WTA circuit employed in this study, a concise examination of the conventional Lazzaro WTA circuit is referenced [29]. The Lazzaro WTA circuit setup involves neurons interconnected, sharing a common current, as depicted in Figure 5. Each neuron represents a distinct class and independently manages its input and output functions. Among these neurons, the one receiving the highest input current generates a non-zero output equal to , while the rest produce an output of zero. Scenarios with similar input currents may result in multiple winners, a situation often considered undesirable in most classification contexts.
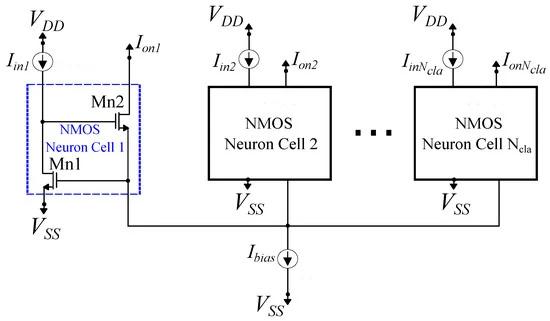
Figure 5. A -neuron standard Lazzaro NMOS winner-takes-all (WTA) circuit.
One approach to tackle this challenge involves implementing a cascaded WTA circuit, illustrated in Figure 6. This devised setup integrates three WTA circuits interconnected in a cascaded manner [83]. Figure 7 provides visual representations of the one-dimensional decision boundaries for both the traditional Lazzaro WTA circuit and the proposed cascaded version. Notably, the cascaded WTA circuit exhibits considerably sharper decision boundaries compared to the basic Lazzaro WTA circuit. As a result, the cascaded topology emerges as the more-suitable choice for the critical argmax operation of the classifier (though argmin might be more appropriate for a generic classifier). The transistor dimensions for both the NMOS and PMOS neurons in Figure 6 were configured at =0.4μm/1.6μm. The preference for elongated transistors was driven by the necessity for reduced noise and enhanced linearity, which are pivotal for the effective execution of the argmax operator.

Figure 6. A cascaded NMOS–PMOS–NMOS WTA circuit. It is utilized to improve the performance of the standard WTA circuit.

Figure 7. Decision boundaries of the standard and the cascaded WTA circuit.
4. Application Example and Simulation Results
In this segment, the performance of the proposed classifier is evaluated using real-world data related to cardiovascular disease prediction [26] to validate its functionality. The classifier was developed utilizing the Cadence IC suite within a TSMC 90 nm CMOS process. All simulation outcomes were based on the layout (post-layout simulations), represented in Figure 8. This consists of =11features. The Cardiovascular Disease Dataset available on Kaggle presents a comprehensive collection of health-related data associated with individuals susceptible to cardiovascular issues. This dataset encompasses a range of attributes that are vital in predicting the likelihood of cardiovascular disease in patients. It comprises both numerical and categorical features, including age, gender, height, weight, blood pressure measurements, cholesterol levels, glucose levels, and various lifestyle indicators like smoking habits and physical activity. Each entry in this dataset is linked to a binary classification label indicating the presence or absence of cardiovascular disease.
Figure 8. The implemented layout related to the proposed classifier. The common centroid technique is used in order to minimize random effects over PVT variations.
Notably, this dataset provides a rich resource for exploratory data analysis and predictive modeling. It holds records for a considerable number of patients, allowing for robust statistical analysis and ML model training. The dataset’s diversity in features provides a comprehensive scope for feature engineering, model validation, and evaluation, making it an invaluable asset for researchers, data scientists, and healthcare professionals aiming to develop predictive models or derive meaningful insights regarding cardiovascular health and associated risk factors.
Based on the proposed design methodology and the simulation results of the software implementation, the generic RBF-based classifier consists of 2 classes and=11 input dimensions. The high-level architecture of this classifier is illustrated in Figure 1. Specifically, each class comprises two 11-D MDCs, representing the clusters, along with the current mirrors utilized to aggregate the output currents of each cluster (considering we have only one cluster per class). Figure 9 showcases the classification accuracy for both the proposed hardware and software implementations, covering a total of 20 distinct training test cases for the relevant dataset. These results are also summarized in Table 2. Regarding sensitivity analysis, the Monte Carlo histogram displayed in Figure 10, comprising 100 runs, exhibits a mean value of μ84.25% and a standard deviation of 1.23% .

Figure 9. Classification results of the proposed architecture and the equivalent software model on the related dataset over 20 iterations.
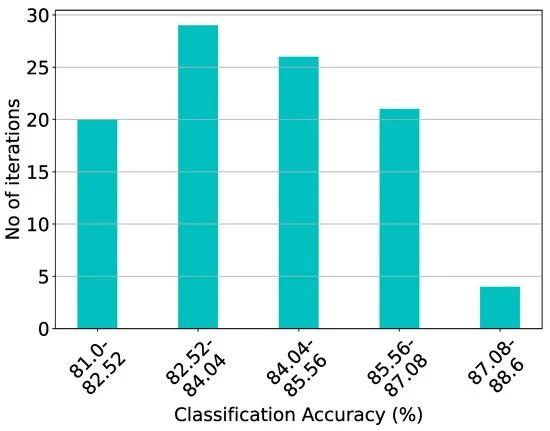
Figure 10. Post-layout Monte Carlo simulation results of the proposed architecture on the related dataset with =84.25% and =1.23%(for 1 of the previous 20 iterations).
Table 2. Proposed architecture’s accuracy for the related dataset (over 20 iterations).
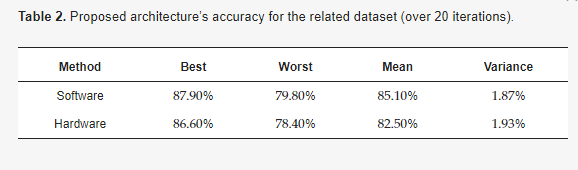
Based on the post-layout results presented, both the individual building blocks and the high-level architecture exhibited the desired behavior. The MDC approached the Mahalanobis distance almost entirely, with slight deviations attributed to mismatches in the mirrors and the early effect phenomenon. It is noteworthy that, for
, the circuit produced the minimum output, which is the desired outcome. Regarding the high-level architecture, the post-layout results demonstrated robust behavior as there was minimal deviation compared to the software accuracy and a slight variance in the Monte Carlo analysis. Furthermore, the nature of the WTA provides a significant advantage even if the currents have small deviations from the theoretical value. Specifically, high or low values will occur at the respective outputs, depending on the difference in the current values, rather than the exact value.
5. Comparison and Discussion
The literature highlights a trend where analog classifiers are predominantly customized for specific applications. Comparing various ML models or hardware implementations on a unified application to derive equitable results poses a significant challenge. However, this challenge presents an opportunity to tailor analog classifiers for a shared application, streamlining performance evaluation encompassing both ML models and alternative methods. Table 3 provides an overview of the performance comparisons across various related classifiers. In the context of cardiovascular classification, the Bayes [36], GMM [36], RBF [36,39], LSTM [71], K-means [55], Bayesian [36], RBF neural network (NN) [41], fuzzy [57], SVM [36,42], threshold [36], MLP [50], SVR [63], and centroid-based [36] classifiers are summarized.
Table 3. Analog classifiers’ comparison on the cardiovascular prediction dataset.
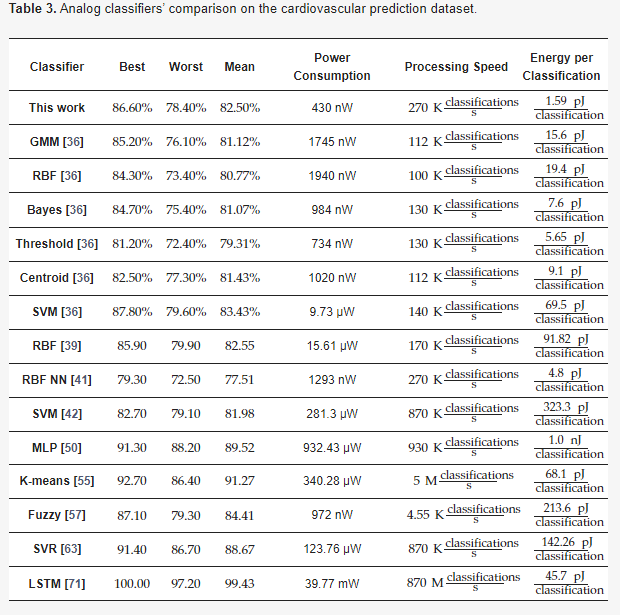
This research proposes a solution that strikes a balance between accuracy, power efficiency, and energy consumption per classification when compared to similar classifiers in the domain. In this particular application, handling high input dimensionality is crucial. The suggested configuration holds a significant advantage by eliminating the need for principal component analysis (PCA), allowing the incorporation of all 11 input dimensions without losing vital information. Moreover, it manages more than 20 features without necessitating PCA, unlike cascaded implementations. In contrast, many alternative structures must reduce the dimensions to 16 or fewer (for more-complex problems) to attain optimal accuracy, a significant limitation in previous similar studies [36,41,42,57,63]. While the proposed classifier exhibits proficiency in accurately classifying a wider range of classes, a binary classification scenario was chosen for a fair comparison with binary analog classifiers [36,57].
Regarding classification accuracy, the proposed architecture surpassed most of its counterparts, except MLP [50], LSTM [71], and K-means [55]. Despite achieving higher accuracy, these models entail increased complexity, power consumption, and a larger silicon area due to component numbers. Conversely, the threshold classifier recorded the lowest power consumption among the other classifiers, albeit sacrificing accuracy and processing speed due to its simplistic model design [36]. In biomedical applications of this nature, swift processing speed is not crucial due to their infrequent occurrence. Hence, in this approach, processing speed is traded for heightened accuracy and optimized power consumption. Additionally, it boasts lower energy consumption per classification compared to all other classifiers.
As shown in Table 3, the proposed implementation achieved the lowest consumption. This confirms the aim of this particular study. More specifically, through the use of the sub-threshold operating region, a significant reduction in consumption was achieved. Additionally, the ability of the circuit itself to operate at very low currents and voltages provides further power efficiency opportunities. Furthermore, through the proposed architecture, there is additional potential for using the minimum possible operating currents. Unlike cascaded implementations (related works), this specific implementation can utilize the full operating range of the circuit, operate at the minimum possible current, and handle a large number of features as there is no current attenuation. Regarding the accuracy of the results, it is primarily related to the approximation of the software model by the hardware. This means that, if the model is too simple and the approximation is not optimal, the accuracy will be low.
6. Conclusions
This research pioneers a new methodology in an adjustable analog integrated Euclidean (Manhattan) distance RBF classifier. By strategically manipulating MDC and WTA circuits, the study showcases the ability to create RBF-based classifiers tailored to a wide array of scenarios, accommodating varied class quantities, cluster setups, and data dimensions. To demonstrate the adaptability and efficiency of this approach, the study applies the proposed design methodology to analyze a distinct real-world dataset curated specifically for diagnosing cardiovascular disease. Comprehensive evaluations and comparisons of classification outcomes within these scenarios emphasize the efficiency of the proposed methodology and validate the adjustments made. This innovative design approach holds promise as a fundamental tool for crafting more-sophisticated and -precise diagnostic systems, offering potential applications across diverse domains where flexible and adjustable classifiers are pivotal for accurate analyses and predictions.
.


